How to Upload Large Files to Aws
AWS : S3 (Simple Storage Service) IV - Uploading a large file
![]()
bogotobogo.com site search:
File Uploading - small files
The code below is based on An Introduction to boto's S3 interface - Storing Data.
To setup boto on Mac:
$ sudo easy_install pip $ sudo pip install boto
Because S3 requires AWS keys, nosotros should provide our keys: AWS_ACCESS_KEY and AWS_ACCESS_SECRET_KEY. The lawmaking uses them from /etc/boto.conf or ~/.boto:
[Credentials] AWS_ACCESS_KEY_ID = A...3 AWS_SECRET_ACCESS_KEY = West...nine
Here is our Python code (s3upload.py):
#!/bin/python import os import argparse import boto import sys from boto.s3.key import Fundamental AWS_ACCESS_KEY = boto.config.get('Credentials', 'aws_access_key_id') AWS_ACCESS_SECRET_KEY = boto.config.get('Credentials', 'aws_secret_access_key') def check_arg(args=None): parser = argparse.ArgumentParser(description='args : starting time/commencement, instance-id') parser.add_argument('-b', '--bucket', assistance='bucket proper name', required='Truthful', default='') parser.add_argument('-f', '--filename', help='file to upload', required='True', default='') results = parser.parse_args(args) return (results.saucepan, results.filename) def upload_to_s3(aws_access_key_id, aws_secret_access_key, file, bucket, fundamental, callback=None, md5=None, reduced_redundancy=Imitation, content_type=None): """ Uploads the given file to the AWS S3 bucket and primal specified. callback is a function of the form: def callback(consummate, full) The callback should accept two integer parameters, the offset representing the number of bytes that have been successfully transmitted to S3 and the second representing the size of the to be transmitted object. Returns boolean indicating success/failure of upload. """ try: size = os.fstat(file.fileno()).st_size except: # Non all file objects implement fileno(), # and so we fall back on this file.seek(0, os.SEEK_END) size = file.tell() conn = boto.connect_s3(aws_access_key_id, aws_secret_access_key) rs = conn.get_all_buckets() for b in rs: print b nonexistent = conn.lookup(bucket) if nonexistent is None: impress 'Not in that location!' bucket = conn.get_bucket(bucket, validate=True) g = Key(bucket) thousand.cardinal = key if content_type: k.set_metadata('Content-Type', content_type) sent = k.set_contents_from_file(file, cb=callback, md5=md5, reduced_redundancy=reduced_redundancy, rewind=True) # Rewind for later use file.seek(0) if sent == size: render True return Simulated if __name__ == '__main__': bucket, filename = check_arg(sys.argv[one:]) file = open(filename, 'r+') print 'ACCESS_KEY=',AWS_ACCESS_KEY print 'ACCESS_SECRET_KEY=',AWS_ACCESS_SECRET_KEY primal = file.name print 'key=',key impress 'saucepan=',bucket if upload_to_s3(AWS_ACCESS_KEY, AWS_ACCESS_SECRET_KEY, file, bucket, cardinal): print 'It worked!' else: print 'The upload failed...' To run, use the following syntax:
python s3upload.py -b saucepan-name -f file-name
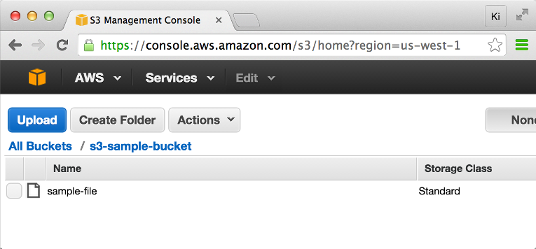
Real sample:
$ python s3upload.py -b s3-sample-saucepan -f sample-file ACCESS_KEY= A... ACCESS_SECRET_KEY= W... key= sample-file saucepan= s3-sample-bucket <Saucepan: s3-sample-bucket> Information technology worked!
File Uploading - Large files
The lawmaking below is based on An Introduction to boto's S3 interface - Storing Large Data.
To make the code to piece of work, we need to download and install boto and FileChunkIO.
To upload a large file, nosotros split the file into smaller components, and then upload each component in plow. The S3 combines them into the last object. The python code below makes use of the FileChunkIO module. And then, we may want to practice
$ pip install FileChunkIO
if it isn't already installed.
Here is our Python code (s3upload2.py):
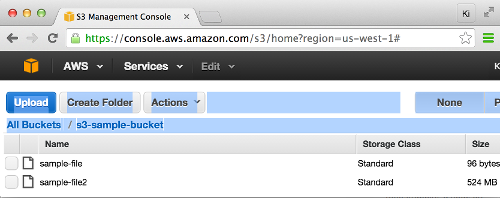
# s3upload.py # Can be used to upload big file to S3 #!/bin/python import os import sys import argparse import math import boto from boto.s3.key import Key from filechunkio import FileChunkIO def check_arg(args=None): parser = argparse.ArgumentParser(clarification='args : showtime/start, instance-id') parser.add_argument('-b', '--bucket', help='bucket name', required='Truthful', default='') parser.add_argument('-f', '--filename', aid='file to upload', required='True', default='') results = parser.parse_args(args) render (results.bucket, results.filename) def upload_to_s3(file, saucepan): source_size = 0 source_path = file.proper name try: source_size = os.fstat(file.fileno()).st_size except: # Not all file objects implement fileno(), # so we autumn back on this file.seek(0, os.SEEK_END) source_size = file.tell() print 'source_size=%s MB' %(source_size/(1024*1024)) aws_access_key = boto.config.get('Credentials', 'aws_access_key_id') aws_secret_access_key = boto.config.get('Credentials', 'aws_secret_access_key') conn = boto.connect_s3(aws_access_key, aws_secret_access_key) bucket = conn.get_bucket(bucket, validate=True) impress 'bucket=%s' %(bucket) # Create a multipart upload request mp = saucepan.initiate_multipart_upload(os.path.basename(source_path)) # Use a chunk size of 50 MiB (experience free to change this) chunk_size = 52428800 chunk_count = int(math.ceil(source_size / chunk_size)) print 'chunk_count=%south' %(chunk_count) # Send the file parts, using FileChunkIO to create a file-similar object # that points to a certain byte range within the original file. We # set bytes to never exceed the original file size. sent = 0 for i in range(chunk_count + ane): start = chunk_size * i bytes = min(chunk_size, source_size - offset) sent = sent + bytes with FileChunkIO(source_path, 'r', first=offset, bytes=bytes) as fp: mp.upload_part_from_file(fp, part_num=i + one) print '%southward: sent = %southward MBytes ' %(i, sent/1024/1024) # Stop the upload mp.complete_upload() if sent == source_size: return True return False if __name__ == '__main__': ''' Usage: python s3upload.py -b s3-sample-saucepan -f sample-file2 ''' bucket, filename = check_arg(sys.argv[1:]) file = open(filename, 'r+') if upload_to_s3(file, bucket): impress 'Information technology works!' else: print 'The upload failed...' The code takes two args: bucket-name and file-name:
/Users/kihyuckhong/DATABACKUP_From_EC2$ python s3upload2.py -b s3-sample-bucket -f sample-file2 source_size=524 MB bucket=<Saucepan: s3-sample-bucket> chunk_count=10 0: sent = 50 MBytes one: sent = 100 MBytes 2: sent = 150 MBytes 3: sent = 200 MBytes 4: sent = 250 MBytes 5: sent = 300 MBytes half-dozen: sent = 350 MBytes 7: sent = 400 MBytes 8: sent = 450 MBytes 9: sent = 500 MBytes 10: sent = 524 MBytes Information technology works!
AWS (Amazon Web Services)
- AWS : EKS (Elastic Container Service for Kubernetes)
- AWS : Creating a snapshot (cloning an image)
- AWS : Attaching Amazon EBS volume to an case
- AWS : Adding swap space to an fastened volume via mkswap and swapon
- AWS : Creating an EC2 instance and attaching Amazon EBS volume to the instance using Python boto module with User information
- AWS : Creating an instance to a new region by copying an AMI
- AWS : S3 (Unproblematic Storage Service) 1
- AWS : S3 (Unproblematic Storage Service) 2 - Creating and Deleting a Saucepan
- AWS : S3 (Elementary Storage Service) 3 - Bucket Versioning
- AWS : S3 (Elementary Storage Service) iv - Uploading a large file
- AWS : S3 (Simple Storage Service) five - Uploading folders/files recursively
- AWS : S3 (Simple Storage Service) 6 - Bucket Policy for File/Folder View/Download
- AWS : S3 (Simple Storage Service) 7 - How to Copy or Move Objects from 1 region to another
- AWS : S3 (Simple Storage Service) 8 - Archiving S3 Data to Glacier
- AWS : Creating a CloudFront distribution with an Amazon S3 origin
- AWS : Creating VPC with CloudFormation
- AWS : WAF (Web Awarding Firewall) with preconfigured CloudFormation template and Web ACL for CloudFront distribution
- AWS : CloudWatch & Logs with Lambda Function / S3
- AWS : Lambda Serverless Calculating with EC2, CloudWatch Alarm, SNS
- AWS : Lambda and SNS - cross account
- AWS : CLI (Control Line Interface)
- AWS : CLI (ECS with ALB & autoscaling)
- AWS : ECS with cloudformation and json job definition
- AWS Application Load Balancer (ALB) and ECS with Flask app
- AWS : Load Balancing with HAProxy (Loftier Availability Proxy)
- AWS : VirtualBox on EC2
- AWS : NTP setup on EC2
- AWS: jq with AWS
- AWS & OpenSSL : Creating / Installing a Server SSL Certificate
- AWS : OpenVPN Admission Server 2 Install
- AWS : VPC (Virtual Private Cloud) 1 - netmask, subnets, default gateway, and CIDR
- AWS : VPC (Virtual Private Cloud) 2 - VPC Sorcerer
- AWS : VPC (Virtual Private Cloud) three - VPC Wizard with NAT
- DevOps / Sys Admin Q & A (VI) - AWS VPC setup (public/private subnets with NAT)
- AWS - OpenVPN Protocols : PPTP, L2TP/IPsec, and OpenVPN
- AWS : Autoscaling group (ASG)
- AWS : Setting upwardly Autoscaling Alarms and Notifications via CLI and Cloudformation
- AWS : Adding a SSH User Account on Linux Example
- AWS : Windows Servers - Remote Desktop Connections using RDP
- AWS : Scheduled stopping and starting an case - python & cron
- AWS : Detecting stopped instance and sending an alert email using Mandrill smtp
- AWS : Elastic Beanstalk with NodeJS
- AWS : Elastic Beanstalk Inplace/Rolling Blue/Greenish Deploy
- AWS : Identity and Access Management (IAM) Roles for Amazon EC2
- AWS : Identity and Access Direction (IAM) Policies, sts AssumeRole, and delegate access across AWS accounts
- AWS : Identity and Admission Management (IAM) sts assume part via aws cli2
- AWS : Creating IAM Roles and associating them with EC2 Instances in CloudFormation
- AWS Identity and Access Management (IAM) Roles, SSO(Unmarried Sign On), SAML(Security Assertion Markup Language), IdP(identity provider), STS(Security Token Service), and ADFS(Agile Directory Federation Services)
- AWS : Amazon Route 53
- AWS : Amazon Route 53 - DNS (Domain Name Server) setup
- AWS : Amazon Route 53 - subdomain setup and virtual host on Nginx
- AWS Amazon Road 53 : Private Hosted Zone
- AWS : SNS (Simple Notification Service) instance with ELB and CloudWatch
- AWS : Lambda with AWS CloudTrail
- AWS : SQS (Uncomplicated Queue Service) with NodeJS and AWS SDK
- AWS : Redshift information warehouse
- AWS : CloudFormation
- AWS : CloudFormation Bootstrap UserData/Metadata
- AWS : CloudFormation - Creating an ASG with rolling update
- AWS : Cloudformation Cross-stack reference
- AWS : OpsWorks
- AWS : Network Load Balancer (NLB) with Autoscaling grouping (ASG)
- AWS CodeDeploy : Deploy an Application from GitHub
- AWS EC2 Container Service (ECS)
- AWS EC2 Container Service (ECS) II
- AWS Hello Earth Lambda Function
- AWS Lambda Part Q & A
- AWS Node.js Lambda Function & API Gateway
- AWS API Gateway endpoint invoking Lambda function
- AWS API Gateway invoking Lambda function with Terraform
- AWS API Gateway invoking Lambda function with Terraform - Lambda Container
- Amazon Kinesis Streams
- AWS: Kinesis Data Firehose with Lambda and ElasticSearch
- Amazon DynamoDB
- Amazon DynamoDB with Lambda and CloudWatch
- Loading DynamoDB stream to AWS Elasticsearch service with Lambda
- Amazon ML (Machine Learning)
- Simple Systems Managing director (SSM)
- AWS : RDS Connecting to a DB Example Running the SQL Server Database Engine
- AWS : RDS Importing and Exporting SQL Server Information
- AWS : RDS PostgreSQL & pgAdmin Iii
- AWS : RDS PostgreSQL 2 - Creating/Deleting a Table
- AWS : MySQL Replication : Main-slave
- AWS : MySQL backup & restore
- AWS RDS : Cross-Region Read Replicas for MySQL and Snapshots for PostgreSQL
- AWS : Restoring Postgres on EC2 instance from S3 fill-in
- AWS : Q & A
- AWS : Security
- AWS : Scaling-Up
- AWS : Networking
Source: https://www.bogotobogo.com/DevOps/AWS/aws_S3_uploading_large_file.php
0 Response to "How to Upload Large Files to Aws"
Post a Comment